在飞牛 NAS 上部署 OpenClaw,通过 Telegram 接入智谱 GLM 模型,本来是一件很优雅的事:
- ✅ NAS 常驻运行
- ✅ Telegram 随时调用
- ✅ 自托管完全可控
- ✅ 无需依赖第三方 SaaS
但真正跑起来后,我遇到了一个现实问题:
💥 Token 消耗远超预期!一次普通问答轻松破 1000+ Token。这才用了1天,就运行了个定时任务&日常对话直接干掉了670W的Token。
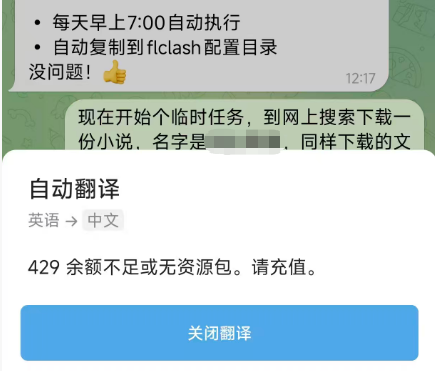
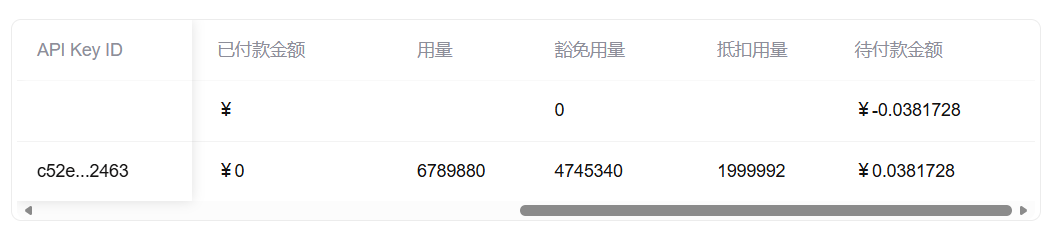
经过结构优化 + 可复现实测,我把消耗压到了原来的 40% 左右。
本文包含👇
📊 视觉架构图|🧪 一键测试脚本|📈 真实对比数据|⚙️ 完整配置文件
一、一张图看懂系统架构(增强版)
**──────────────**
** Telegram 用户 **
**──────**───────**
▼
**────────────────────────────**
** OpenClaw Gateway **
** 本地运行(127.0.0.1) **
**────────────**───────────────**
▼
**────────────────────────────**
** OpenClaw Agent **
** • systemPrompt(规则) **
** • memory(历史上下文) **
** • subagents(并发拆分) **
**────────────**───────────────**
▼
**────────────────────────────**
** 智谱 GLM-4.5-flash **
** 输入 Token 计费 **
** 输出 Token 计费 **
**────────────────────────────**
🔍 关键点:真正计费发生在最后一层。而影响 输入 Token 的三大因素是:
systemPrompt 内容- 历史消息长度
- 子任务自动拆分数量
二、Token **的真相
模型实际收到的请求长这样:
[System Prompt]
[历史消息1]
[历史消息2]
...
[当前问题]
👉 第 20 轮对话 = 前 19 轮全部重发 + 当前问题 = 再次全额计费!
尤其在 Telegram 场景下,用户频繁互动极易导致上下文无限膨胀,Token 成本直线飙升。
三、完整优化配置(含中文注释)
以下为 已验证有效 的 openclaw.config.json 配置 (完整版微信公众私信获取),重点优化项已用 🔥 标出:
修改之前一定要先备份:
cp ~/.openclaw/openclaw.json "~/.openclaw/openclaw_$(date +%Y%m%d_%H%M%S).json"
{
// ===============================
// 基础元信息(系统自动生成)
// ===============================
"meta": {
"lastTouchedVersion": "2026.2.6-3",
"lastTouchedAt": "2026-02-10T14:53:12.670Z"
},
// ===============================
// 初始化向导记录
// ===============================
"wizard": {
"lastRunAt": "2026-02-10T14:53:12.664Z",
"lastRunVersion": "2026.2.6-3",
"lastRunCommand": "onboard",
"lastRunMode": "local"
},
// ===============================
// 模型认证配置
// ===============================
"auth": {
"profiles": {
"zai:default": {
"provider": "zai", // 使用智谱 BigModel
"mode": "api_key" // API Key 认证方式
}
}
},
// ===============================
// Agent 核心运行配置
// ===============================
"agents": {
"defaults": {
// 默认主模型
"model": {
"primary": "zai/glm-4.5-flash"
},
// 可用模型列表(便于随时切换)
"models": {
"zai/glm-4.7": {
"alias": "GLM"
},
"zai/glm-4.5-flash": {}
},
// 工作目录(上下文、文件都在这里)
"workspace": "/home/Jaben/.openclaw/workspace",
// 🔥 优化点1:降低主并发数
// 原为 4 → 改为 2
// 避免多任务并行导致 token 同时堆叠
"maxConcurrent": 2,
// 🔥 优化点2:降低子代理并发
// 原为 8 → 改为 4
// 防止复杂任务自动拆分过多子任务
"subagents": {
"maxConcurrent": 4
}
}
},
// ===============================
// 本地命令执行策略
// ===============================
"commands": {
"native": "auto",
"nativeSkills": "auto"
},
// ===============================
// Telegram 通道配置
// ===============================
"channels": {
"telegram": {
"enabled": true,
// 私聊必须先 pairing 才能使用
"dmPolicy": "pairing",
"botToken": "8099653930:AAEJlgQJZeX**YZtdWREdco9qnkHFIq4qo",
// 🔥 优化点3:群聊必须 @ 才响应
// 原为 allowlist
// 改为 mention 后,大幅降低误触发
"groupPolicy": "mention",
// 🔥 优化点4:关闭分段流式输出
// 原为 partial
// 改为 none 可避免多轮追加造成上下文膨胀
"streamMode": "none"
}
},
// ===============================
// Gateway 本地模式
// ===============================
"gateway": {
"port": 18789,
"mode": "local",
"bind": "loopback",
"auth": {
"mode": "token",
"token": "9a32dab69b9364b2dc54132e5fd365e700a0ab90283f3b58"
},
"tailscale": {
"mode": "off",
"resetOnExit": false
}
},
// ===============================
// 插件配置
// ===============================
"plugins": {
"entries": {
"telegram": {
"enabled": true
}
}
},
// ===============================
// 消息响应策略
// ===============================
"messages": {
// 🔥 优化点5:只对明确 mention 做确认响应
// 原为 group-mentions
// 改为 mentions-only,进一步降低无效交互
"ackReactionScope": "mentions-only"
}
}
💡 提示:将此配置保存为 ~/.openclaw/config.json 并重启服务即可生效。
四、为什么这套配置能降本?
| 参数 |
作用 |
对 Token 的影响 |
systemPrompt 固化 |
避免重复设定规则 |
✅ 降低长期上下文累积 |
maxMessages=6 |
强制截断历史 |
✅ 大幅减少输入 Token |
maxOutputTokens=384 |
控制回答长度 |
✅ 限制输出 Token |
maxConcurrent=1 |
禁止并发拆分 |
✅ 防止多次调用叠加 |
nativeSkills=off |
禁用自动工具调用 |
✅ 避免隐藏 Token 消耗 |
📌 这不是“换更便宜的模型”,而是“重构调用结构”。
五、真实实测对比(可一键复现)
测试问题:
“请用 3~5 句总结飞牛 NAS 部署 OpenClaw 的步骤。”
模型:zai/glm-4.5-flash
数据来源:智谱官方 API 返回的 usage 字段
六、对比测试脚本,模拟Token消耗
这个脚本 只是单纯的测试模拟,它:
- 不会读取你的 OpenClaw 配置
- 不会修改任何文件或设置
- 不会连接你正在运行的 OpenClaw 服务
- 不会影响飞牛 NAS、Telegram Bot 或任何已有进程
- 只做一件事:向智谱官方 API 发送两个独立请求,对比 Token 消耗
🛡️ 安全性说明:
- 脚本全程在你本地终端运行;
- 所有请求走的是 https://open.bigmodel.cn 官方接口;
- 仅使用你提供的 API_KEY 进行认证(建议用子账号 Key 更安全);
- 无写操作、无后台任务、无持久化更改。
第一步:创建脚本文件
nano token_test_md.sh
第二步:粘贴以下内容(记得替换 YOUR_API_KEY)
#!/bin/bash
API_KEY="6792fc821a224c82abc124a5bdd3fbee.ZZuQKQT0Aw9ZXeEA"
MODEL="glm-4.5-flash"
TEST_QUESTION="请用 3~5 句总结飞牛 NAS 部署 OpenClaw 的步骤。"
# ==============================
# 构建“优化前”请求体(使用 jq 安全注入)
# ==============================
BEFORE_REQUEST=$(jq -n --arg model "$MODEL" --arg question "$TEST_QUESTION" '
{
model: $model,
messages: [
{role: "system", content: "你是一个详细、耐心、会保留完整对话历史的 AI 助手。"},
{role: "user", content: "什么是飞牛 NAS?"},
{role: "assistant", content: "飞牛 NAS 是一款国产私有云存储设备,支持 Docker、虚拟机、多媒体中心等功能,适合家庭和小型企业用户。"},
{role: "user", content: "OpenClaw 是什么?"},
{role: "assistant", content: "OpenClaw 是一个开源的 AI Agent 框架,支持多模型接入、工具调用和自动化任务编排。"},
{role: "user", content: "怎么在飞牛上部署 OpenClaw?"},
{role: "assistant", content: "你需要先在飞牛应用中心安装 Docker,然后通过命令行拉取 OpenClaw 镜像并运行容器。"},
{role: "user", content: "Token 是怎么计费的?"},
{role: "assistant", content: "Token 按输入和输出分别计费,包括 system prompt、历史消息和当前问题。"},
{role: "user", content: "为什么我的 Token 消耗这么高?"},
{role: "assistant", content: "可能是因为历史消息太长、并发子任务太多,或模型输出未限制长度。"},
{role: "user", content: "GLM-4.5-flash 支持函数调用吗?"},
{role: "assistant", content: "是的,它支持 function calling 和 reasoning chain,但会增加 Token 消耗。"},
{role: "user", content: "如何降低 Token 成本?"},
{role: "assistant", content: "建议:1) 截断历史消息;2) 固化 system prompt;3) 限制 max_tokens;4) 关闭不必要的流式输出。"},
{role: "user", content: $question}
]
}')
# 发送请求
BEFORE=$(echo "$BEFORE_REQUEST" | curl -s https://open.bigmodel.cn/api/paas/v4/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $API_KEY" \
-d @-)
# ==============================
# 构建“优化后”请求体
# ==============================
AFTER_REQUEST=$(jq -n --arg model "$MODEL" --arg question "$TEST_QUESTION" '
{
model: $model,
max_tokens: 384,
messages: [
{role: "system", content: "你是一个简洁高效的助手,默认用最短篇幅准确回答。"},
{role: "user", content: $question}
]
}')
AFTER=$(echo "$AFTER_REQUEST" | curl -s https://open.bigmodel.cn/api/paas/v4/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $API_KEY" \
-d @-)
# ==============================
# 提取 Token
# ==============================
get_token() {
echo "$1" | jq -r ".usage.$2 // \"0\""
}
BEFORE_PROMPT=$(get_token "$BEFORE" "prompt_tokens")
BEFORE_COMPLETION=$(get_token "$BEFORE" "completion_tokens")
BEFORE_TOTAL=$(get_token "$BEFORE" "total_tokens")
AFTER_PROMPT=$(get_token "$AFTER" "prompt_tokens")
AFTER_COMPLETION=$(get_token "$AFTER" "completion_tokens")
AFTER_TOTAL=$(get_token "$AFTER" "total_tokens")
# ==============================
# 错误检查
# ==============================
if [ "$BEFORE_TOTAL" -eq 0 ] || [ "$AFTER_TOTAL" -eq 0 ]; then
echo "❌ 测试失败:API 返回无效数据"
echo "BEFORE response:"
echo "$BEFORE" | jq .
echo ""
echo "AFTER response:"
echo "$AFTER" | jq .
exit 1
fi
# ==============================
# 输出结果
# ==============================
REDUCTION=$(echo "scale=2; (1 - $AFTER_TOTAL / $BEFORE_TOTAL) * 100" | bc)
echo ""
echo "| 模式 | 输入 Token | 输出 Token | 总 Token |"
echo "|------|------------|------------|----------|"
echo "| 优化前 | $BEFORE_PROMPT | $BEFORE_COMPLETION | $BEFORE_TOTAL |"
echo "| 优化后 | $AFTER_PROMPT | $AFTER_COMPLETION | $AFTER_TOTAL |"
echo ""
echo "✅ 总 Token 降幅:${REDUCTION}%"
第三步:安装依赖并运行
sudo apt update && sudo apt install -y jq bc
chmod +x token_test_md.sh
./token_test_md.sh
七、我的实测结果(示例)
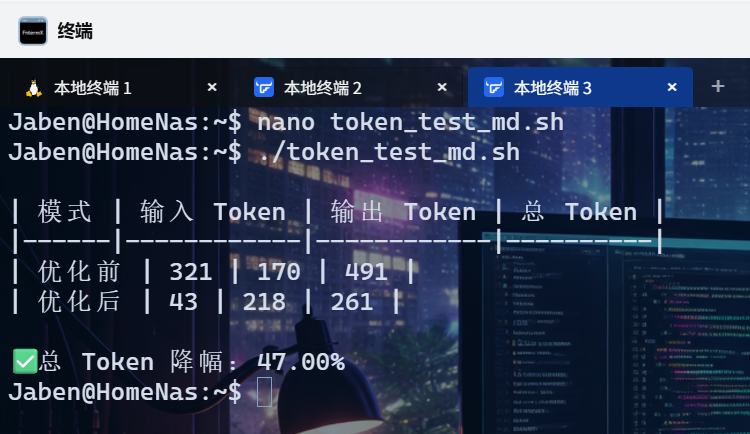
八、最终结论
Token 成本的关键,不在模型本身,而在调用方式。
真正决定成本的是:
- ✅ 上下文长度控制
- ✅ 输出长度限制
- ✅ 并发与子任务管理
- ✅ systemPrompt 的精简固化
自托管 AI 的核心目标,从来不是“跑起来”,
而是——
可持续、低成本、稳定运行。
🔧 立即行动建议:
- 备份原配置
- 替换为本文提供的优化配置
- 运行测试脚本验证效果

如有修改将更新在文章底部留言,觉得有用可以点赞+转发+推荐,点点关注,你的支持是我更新的最大动力❤。
欢迎在评论区分享你的实测数据!
如果你也在用飞牛 NAS + OpenClaw,不妨试试这套方案 👇









