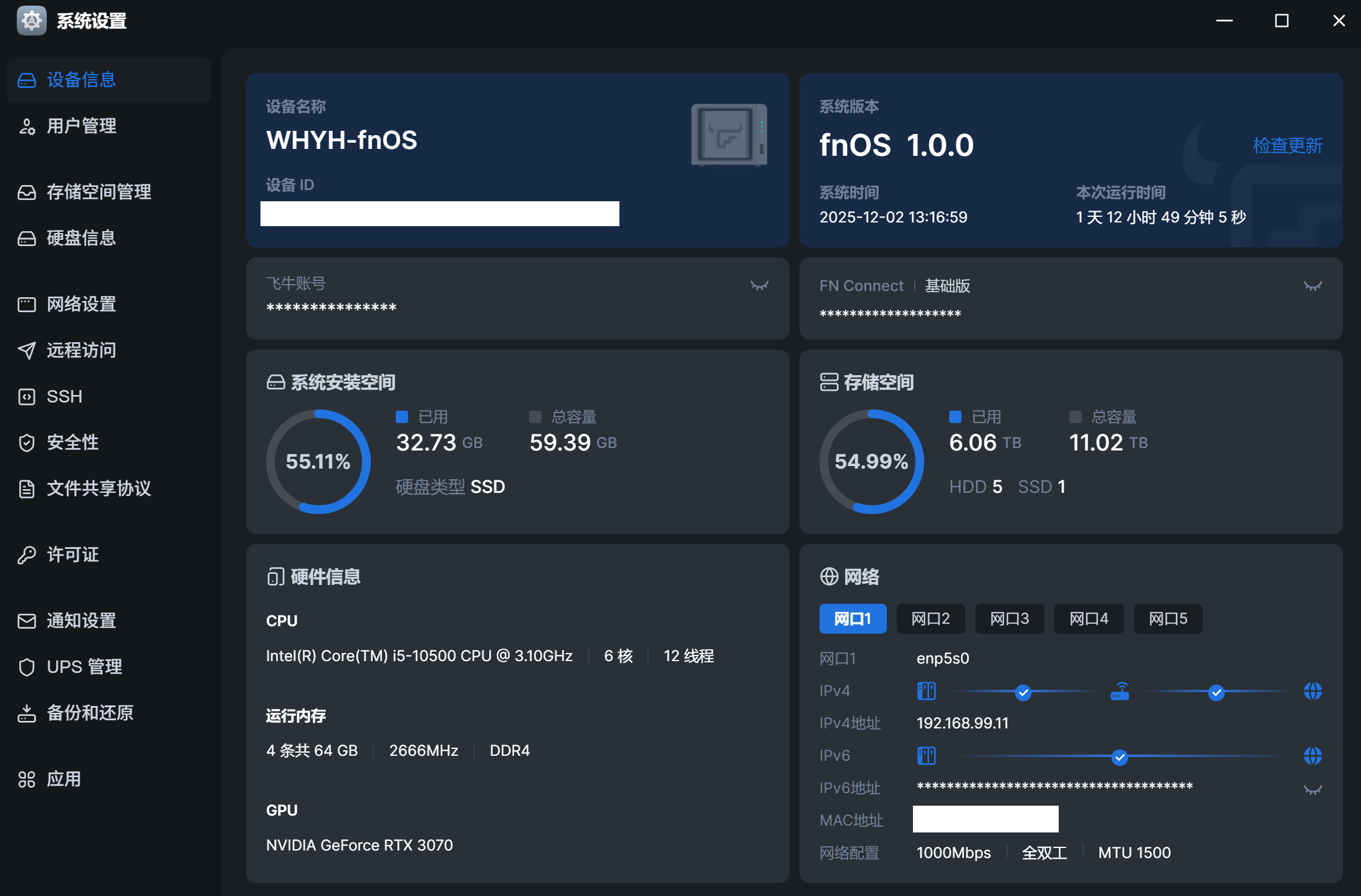
设备型号/版本:
问题描述:
开发团队你好,我是一名 fnOS 用户。在使用过程中,我发现系统的硬盘健康检测逻辑存在“过于敏感”且“误报无法消除”的问题,容易给用户造成不必要的恐慌。希望团队能优化 SMART 状态的判定权重。
具体场景:
我有一块希捷监控盘(4TB),服役时间较长(4.4万小时)。
- 这块盘在 1 年前(3.2万小时)曾产生过 5 个
Reported_Uncorrect (ID 187) 错误。
- 但在随后的 1 万多小时里,该数值一直稳定在 5,未增加。
- 且 ID 5 (Reallocated) 和 ID 197 (Current Pending) 均为 0。
为了确认健康状态,我手动运行了 smartctl -t long(Extended offline)全盘深层扫描。测试结果显示完美通过(PASSED),无任何读写错误。
存在的问题:
尽管 smartctl 的长测试结果显示硬盘当前物理状态健康,但 fnOS 依然因为 ID 187 的历史计数(Raw Value = 5),持续将该硬盘标记为警告状态,且会在一直在通知里面提醒我。
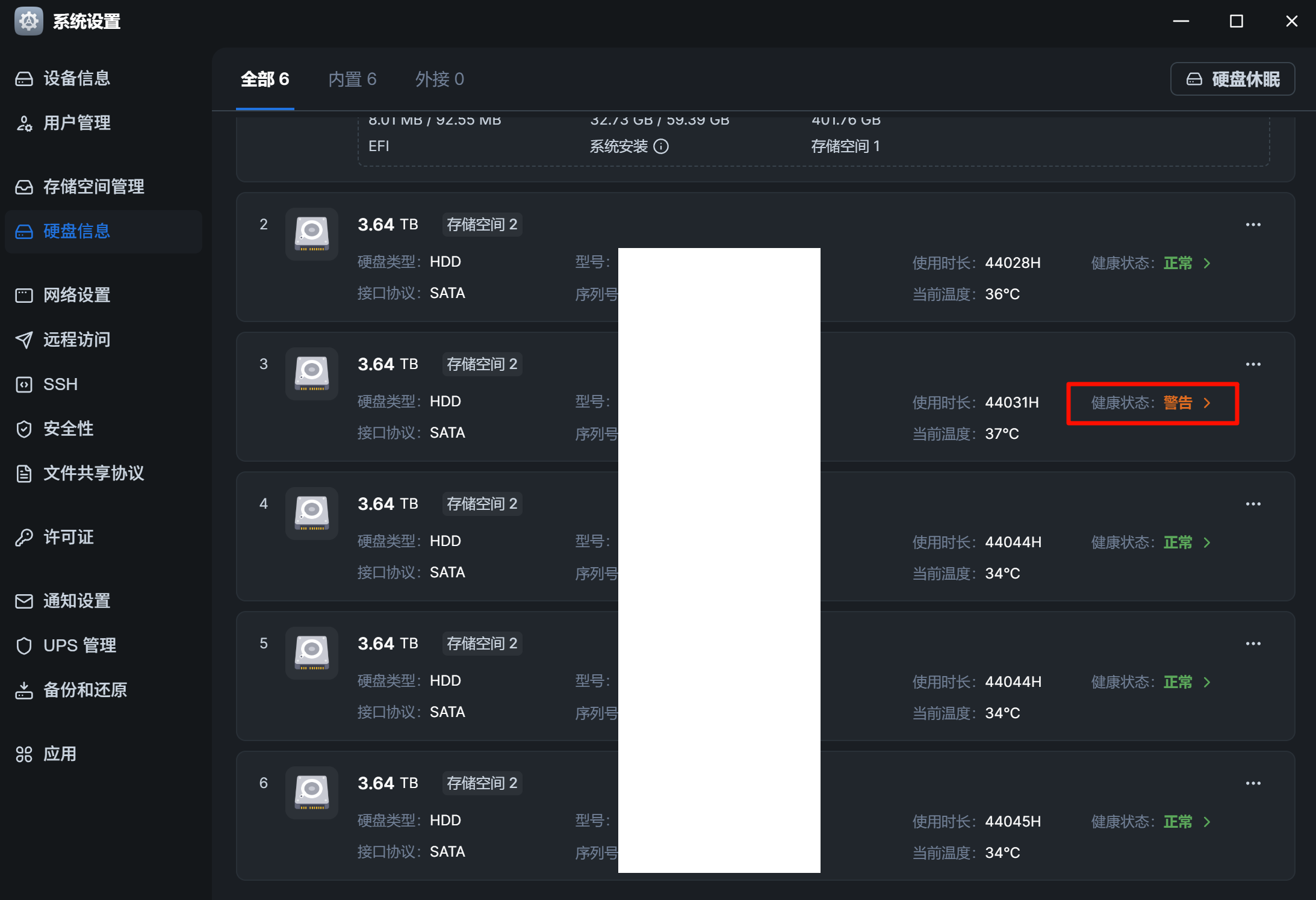
由于 SMART 的某些属性(如 ID 187)是累计计数,物理上不可清零。这意味着这块通过了全盘体检的健康硬盘,在 fnOS 里将永远背负“警告”标签,导致我无法分辨它是真的快挂了,还是只是有历史遗留问题。
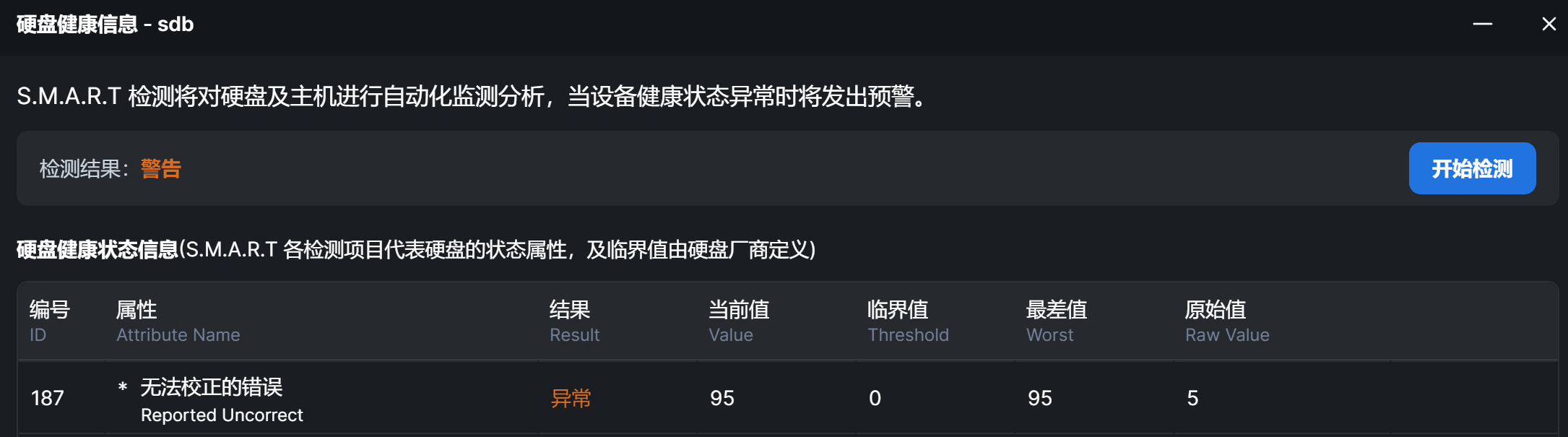
技术证据:
- SMART 属性(历史计数,数值稳定):
187 Reported_Uncorrect 0x0032 095 095 000 Old_age Always - 5
- Extended Self-test 日志(当前真实状态):
# 1 Extended offline Completed without error 00% 44019 -
改进建议:
为了提升专业用户的体验,避免“狼来了”效应,建议在后续版本中加入以下两个功能之一:
方案一:优化判定逻辑,提升“自检结果”权重(推荐) 当系统检测到 SMART 属性异常(如 ID 187/197/198 非零)时,不要直接判死刑。应检查 Self-test log。
- 如果用户最近(例如 24 小时内)成功通过了 Extended offline self-test (
Completed without error),系统应自动将硬盘状态从“警告”降级为“正常”或“需关注”,并消除红点提示。
- 逻辑依据:通过全盘扫描代表磁盘当前物理扇区可读,历史计数不代表当前风险。
方案二:开放 SMART 自定义报警阈值/白名单 允许用户在硬盘管理界面手动设置报警规则。
- 例如:允许用户设置“当 ID 187 增长超过 X 时才报警”,或者允许用户手动“忽略/屏蔽”特定的 SMART ID 报警。
- Linux 底层的
smartd.conf 本身就支持 -I 187 等忽略参数,希望能在 GUI 层面透出这个能力。
期待结果: 希望 fnOS 能更加智能地判断硬盘死活,而不是仅仅死板地读取 SMART 原始值。通过全盘扫描的硬盘,理应获得“健康证”。







 2025-12-2 13:12:55
2025-12-2 13:12:55







 2026-1-12 18:13:27
2026-1-12 18:13:27