这段时间,AI 我是越用越顺手,但也越来越不敢放开用。
原因很简单:API 太贵了。
刚好最近谷歌出了 Gemma 4。
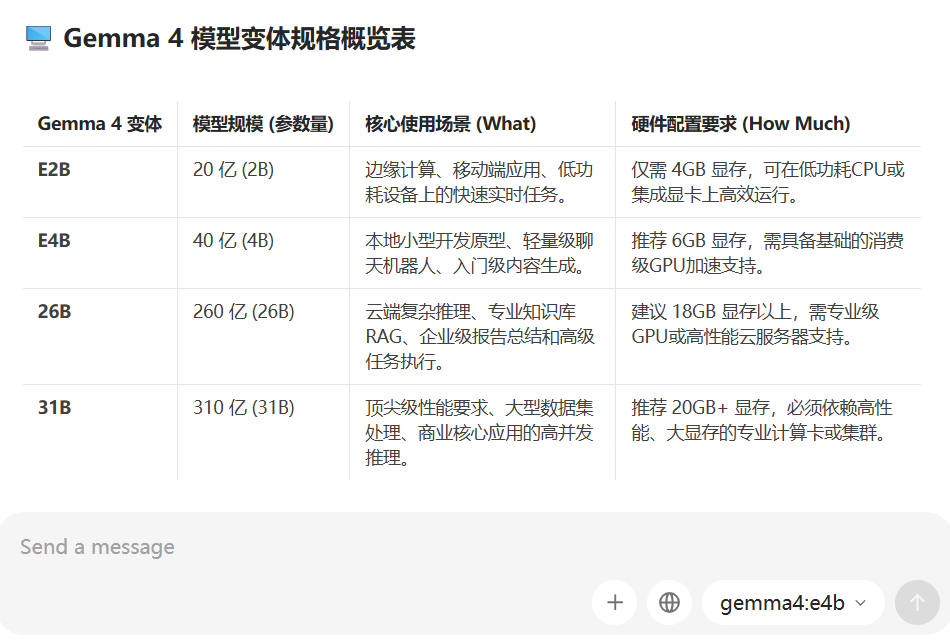
我顺手装了一遍,结果发现这件事比想象中简单很多。
如果你只是想先把一个能用的大模型跑起来,而不是一上来就折腾特别复杂的环境,那这条路其实挺适合的。
我这次就是用 Ollama + Gemma 4,给自己搭了一套本地 AI,还顺手接入Openclaw。
整个过程,核心就三步。
第一步,先把 Ollama 装上
如果你之前没折腾过本地大模型,那可以先把 Ollama 理解成一个“本地模型运行器”。
很多开源模型,都是通过它来下载、启动和运行的。
你不用自己去处理太多底层环境,省心很多。
macOS / Linux
直接执行:
curl -fsSL https://ollama.com/install.sh | sh
Windows
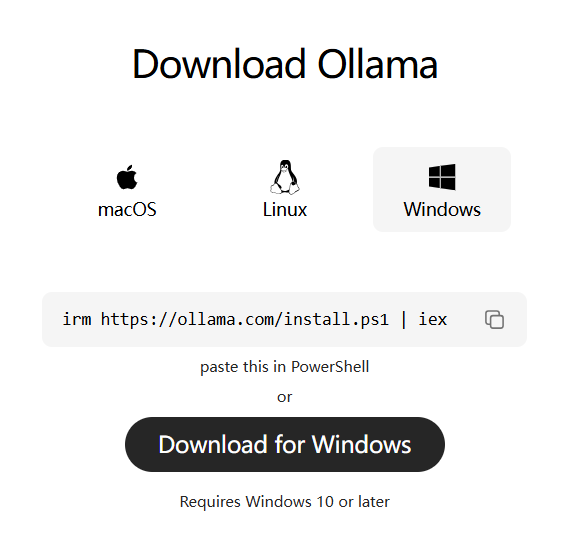
1、去官网下载安装就行:
https://ollama.com
2、PowerShell直接执行:
irm https://ollama.com/install.ps1 | iex
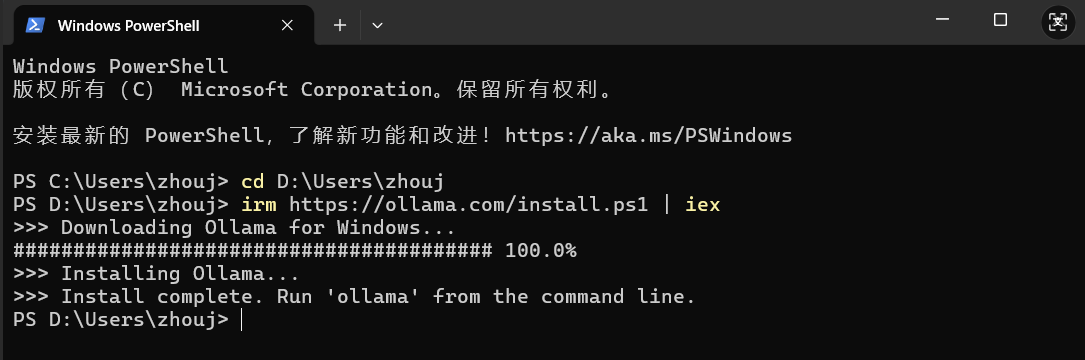
装完之后,可以先确认一下有没有成功:
ollama -v
只要能看到版本号,基本就说明没问题了。
这一步本身不复杂,真正关键的是先把这套基础运行环境搭起来。
后面不只是 Gemma 4,很多别的开源模型你也能直接跑。
第二步,把 Gemma 4 拉到本地
环境有了,接下来就是把模型下载下来。
我这边用的是:
ollama pull gemma4:e4b
第一次拉模型会慢一点,这个主要看网络和模型大小,耐心等它跑完就行。
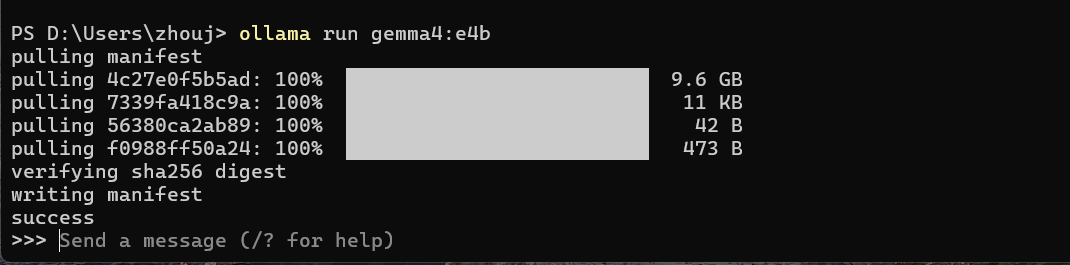
温馨提示:C盘空间不够的话,先更改Ollma模型设置路径
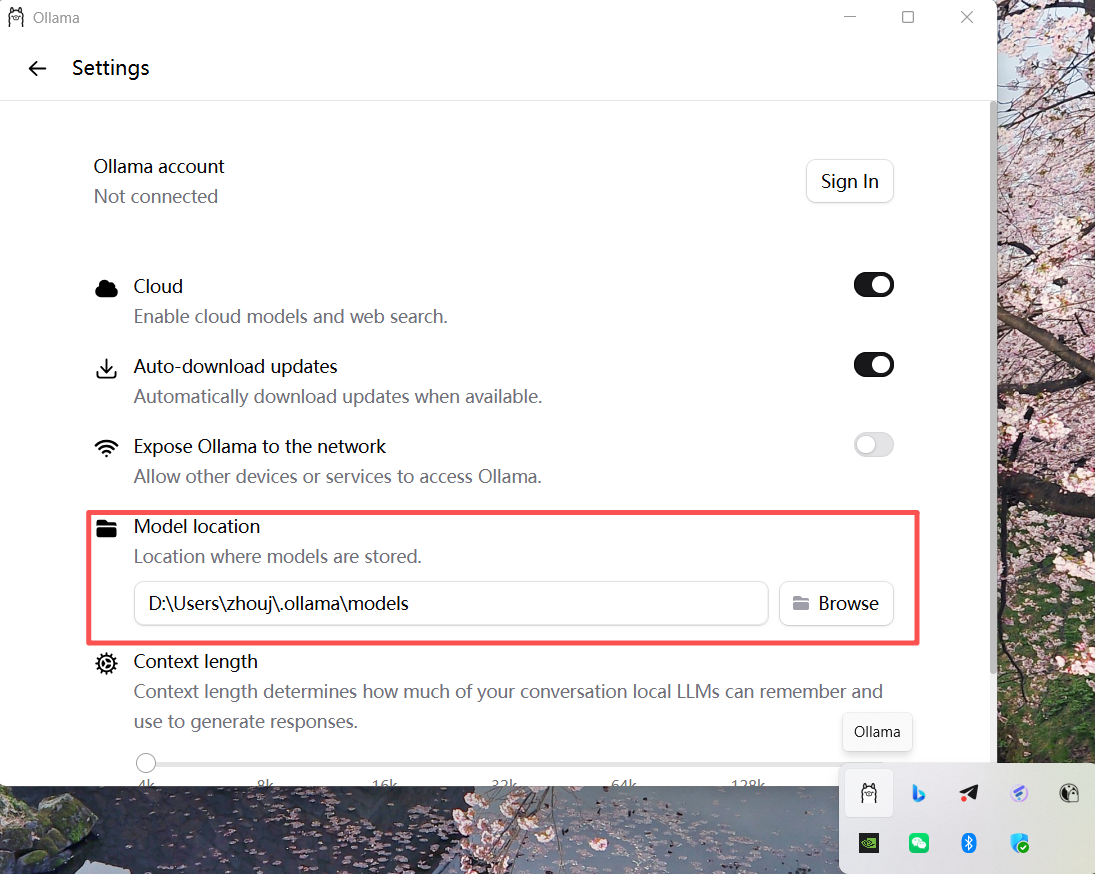
下载完成后,就可以通过Ollma客户端选择已下载的模型:
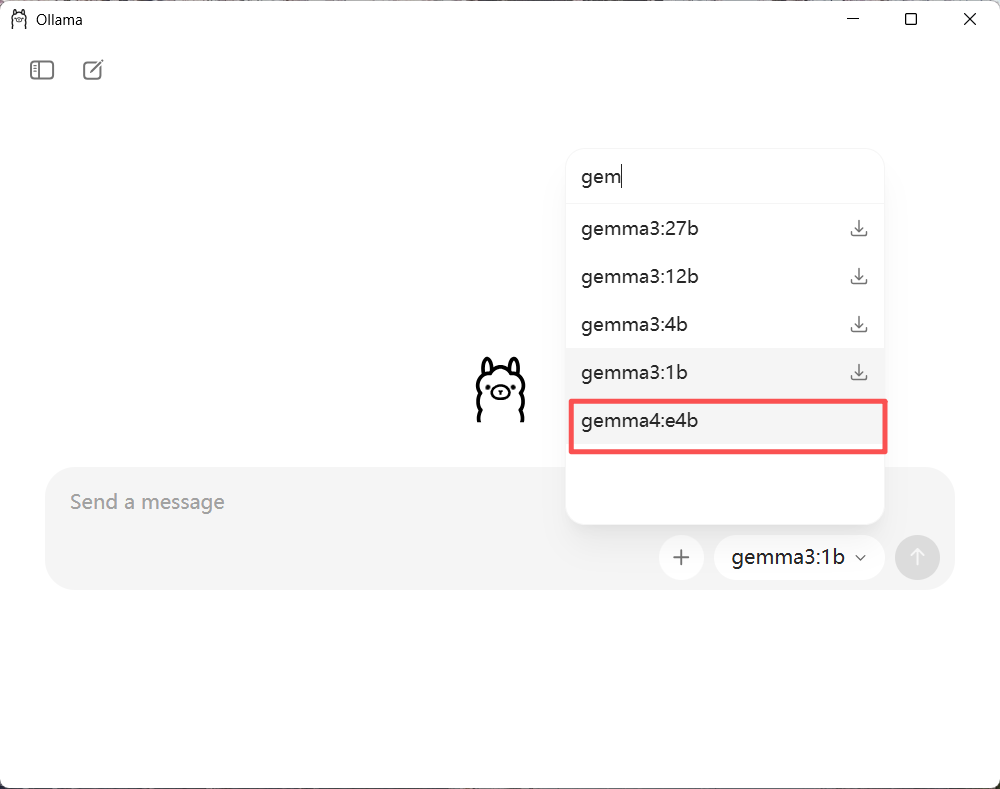
第三步,直接跑起来试一下
你也可以顺手丢一句测试:
你好,你是什么模型?简单介绍一下自己。

如果它能正常回你,那这事基本就成了。
这是本地运行占用资源:
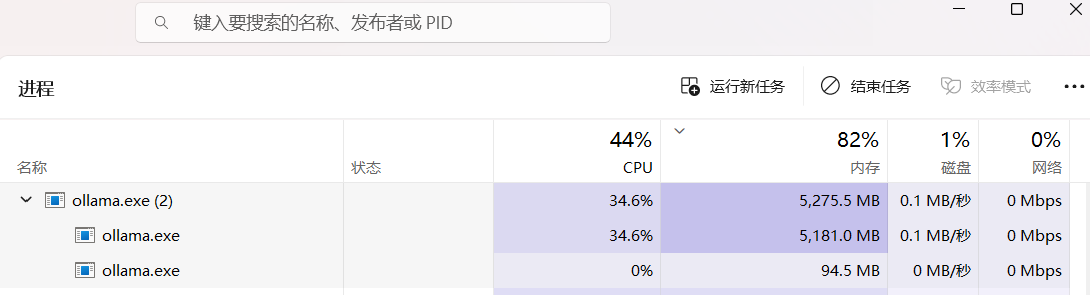
到这里,其实最核心的部分已经结束了。
说到底,就是三步:
没有很多人想象中那么复杂。
Gemma4本地模型接进OpenClaw
1、打开Ollama客户端-Launch复制命令
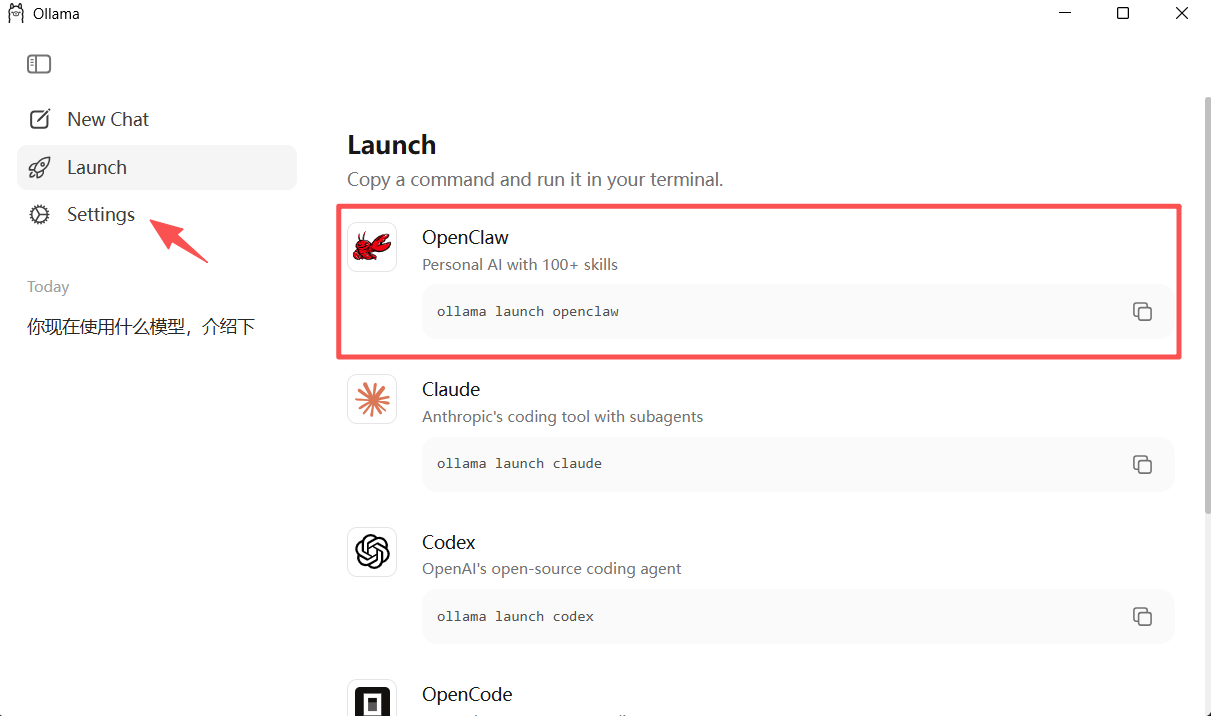
终端运行:
ollama launch openclaw
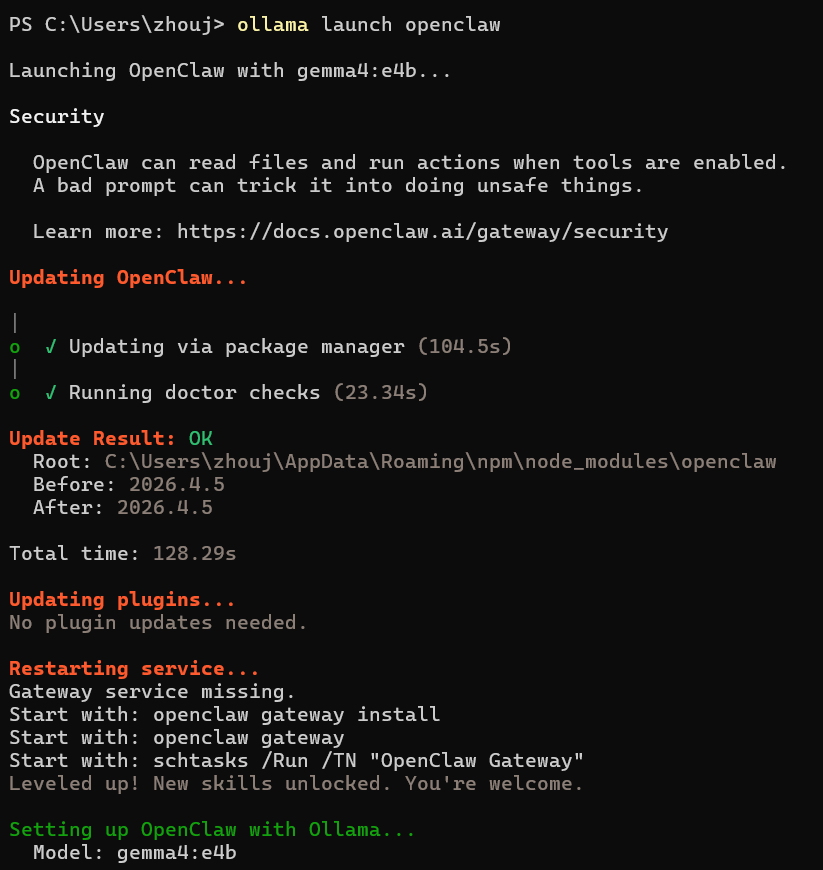
2、系统自动配置
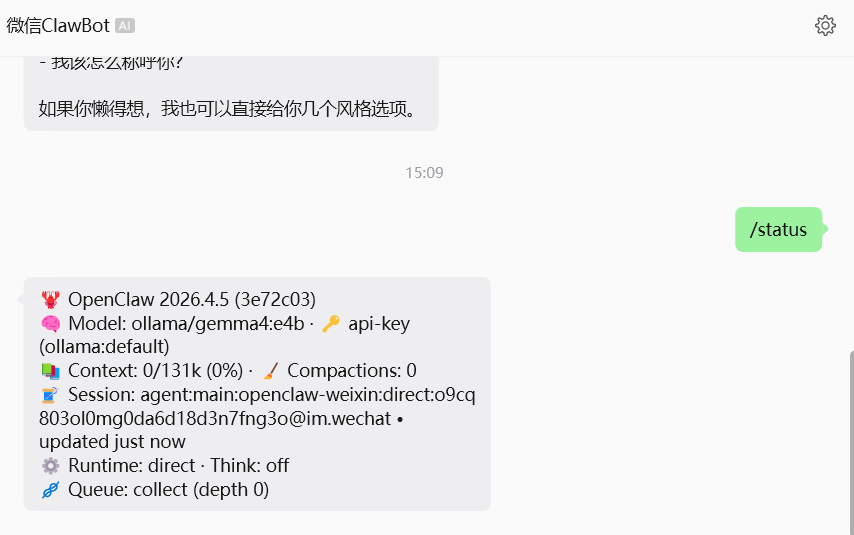
3、Openclaw其它配置就不赘述了
最后
本地跑 Gemma 4,再接入 OpenClaw,最大的好处是省钱、可控,也更方便接自己的工作流。
当然,这套方案也有局限
本地模型的整体能力和稳定性,很多时候还是很难完全替代顶级云端模型,尤其是复杂推理、长上下文和高强度任务。
所以更适合把它理解成:
它不一定能替代所有云端模型,
但至少能把一部分高频、重复、成本敏感的任务搬回本地。
总体四步:
- 装 Ollama
- 拉 Gemma 4
- 跑起来
- 接进 OpenClaw
👥 NAS 折腾交流群
如果你最近也在折腾本地 AI,或者已经把模型接进自己的工作流,欢迎留言聊聊你现在在用什么模型。
想看更多这类 OpenClaw × NAS × AI自动化 的实战内容,欢迎关注公众号 “纳斯派”。
如果你想参与讨论、一起共创玩法,也欢迎公众号私信进群一起交流。







 2026-4-7 22:17:08
2026-4-7 22:17:08


 2026-4-8 18:37:58 楼主
2026-4-8 18:37:58 楼主