接触飞牛OS也已经8个月了,看着硬盘里面的相片和影视资源越来越多,又没有找到单纯的轮播展示应用,于是找AI帮忙手搓一个。
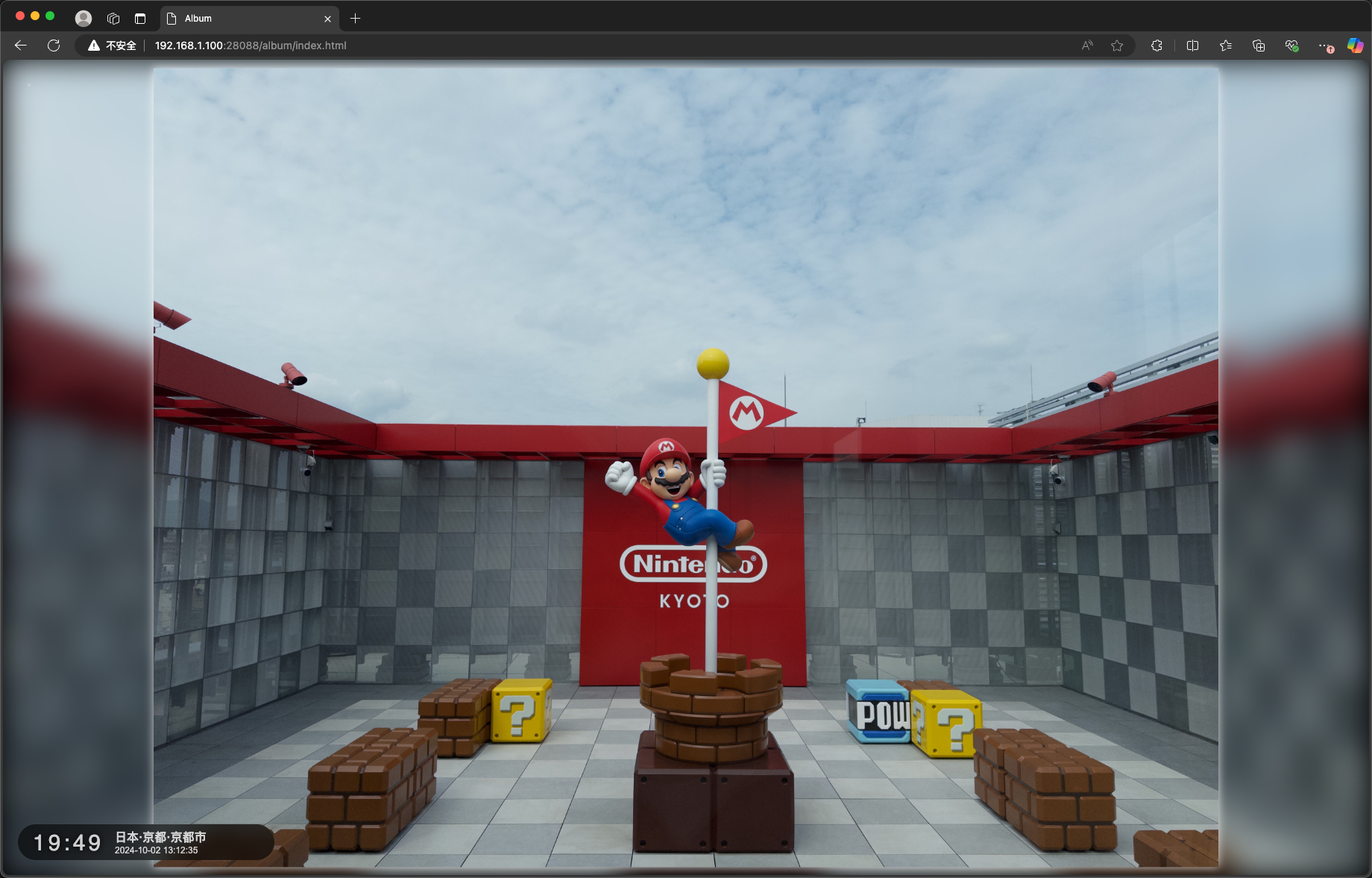
- 相册轮播:支持展示相册位置/地理位置(腾讯地图)和拍摄时间
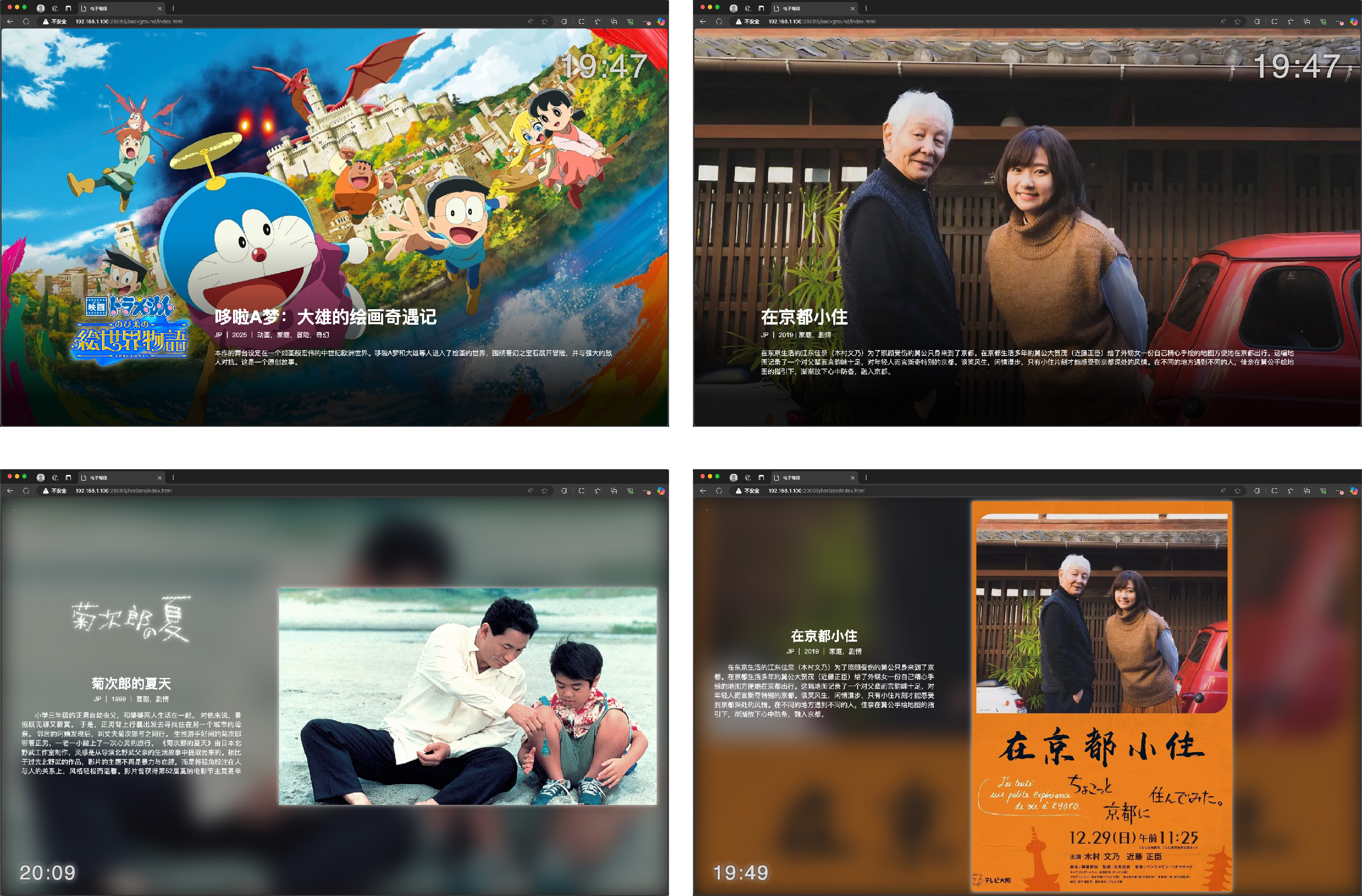
- 影视海报轮播:使用TMDB数据源,可展示背景、海报、logo等信息
项目地址:
宇宙安全声明:项目90%AI+10%人工排bug,主打一个能用就行,你会看到
- 前端:ES5无法兼容,前端资源管理混乱
- 后端:缺少日志,返回信息缺少规范
后端 - JAVA SpringBoot:https://gitee.com/leric-cn/ealbum-back/releases/tag/V2.3.7
前端 - 原生HTML CSS JS :https://gitee.com/leric-cn/ealbum-for-old-device/releases/tag/V3.3.0
页面目录
入口页

相册 /album/index.html

影视展示
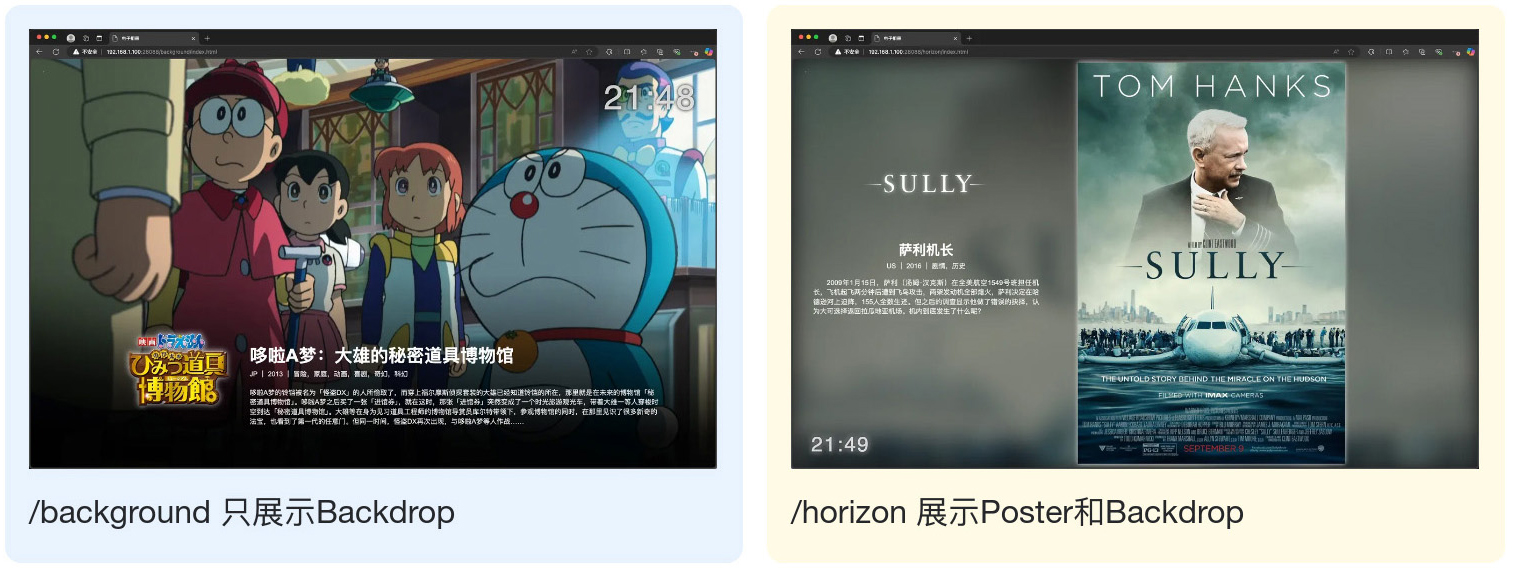
海报

部署说明
1. 账号准备
- 申请TMDB API token
- 申请腾讯地图的应用KEY 并为“”接口分配配额
2. 基础配置
- Nginx 图片服务器
需要通过Nginx配置图片目录/photo;以及转码后的文件目录/convert(如果你需要展示CR2、DNG、HEIC格式的话)。最终图片文件通过这两个地址访问:
- ip:28081/photo/path-to-your-photo.jpg
- ip:28081/converted/path-to-your-photo.jpg
server {
listen 28081;
# 映射/photo路径
location /photo/ {
alias /photo/;
# 图片文件类型优化
location ~* \.(jpg|jpeg|png|gif|webp|svg|bmp)$ {
expires 30d;
add_header Cache-Control "public, no-transform";
}
}
# 映射/converted路径
location /converted/ {
alias /converted/;
# 图片文件类型优化
location ~* \.(jpg|jpeg|png|gif|webp|svg|bmp)$ {
expires 30d;
add_header Cache-Control "public, no-transform";
}
}
}
- Mysql数据库
你需要初始化两个数据库
- episode:存放影视信息,可通过后端初始化接口批量添加或通过TMDB链接逐个添加
CREATE TABLE `episode` (
`id` int NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`media_name` varchar(255) NOT NULL COMMENT '影视名称',
`tmdb_id` int NOT NULL COMMENT 'TMDB编号',
`media_type` enum('Movie','TV') NOT NULL COMMENT '影视类型: Movie 或 TV',
`description` text,
`category` varchar(255) DEFAULT NULL COMMENT '分组信息:1 为不展示 2/3 为自定义分组',
`images` text,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=333 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci COMMENT='剧集信息表';
- albumPath:你相册的目录,目录下需要存在图片,不建议用再放子目录
CREATE TABLE `albumPath` (
`album_path` varchar(255) NOT NULL,
`recommand` tinyint(1) DEFAULT '0',
PRIMARY KEY (`album_path`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
3. 后端配置
- 后端口服务目录
- 新建目录,在目录下放置jar包 EAlbum-BE.jar
- 在子目录./config 中新建项目配置文件 application.properties
Your Path
**── config
** **── application.properties
**── EAlbum-BE.jar
- 后端配置文件
你需要手动配置项目配置文件
# 配置运行端口
server.port=28080
spring.application.name=EAlbum-BE
# Mysql 配置信息
# 如果
spring.datasource.url=jdbc:mysql://<数据库IP:端口>/数据库名称?allowPublicKeyRetrieval=true&useSSL=false&serverTimezone=UTC
spring.datasource.username= 你的数据库用户名
spring.datasource.password= 你的数据库密码
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
# JPA 配置(无需修改)
spring.jpa.show-sql=true
spring.jpa.hibernate.ddl-auto=update
spring.jpa.properties.hibernate.dialect=org.hibernate.dialect.MySQL8Dialect
# 目录配置
# 影视目录 多个地址以英文逗号(,)隔开
paths.movie= /path1,/path2
paths.tv=
# RAW 转码后的图片地址
paths.converted= /converted
# 接口Token配置,如果没有,随便填些什么东西
token.tmdb= tmdb Token
token.feishu= 飞书机器人token
token.tencentMap= 腾讯地图Key
logging.file.name=./EAlbum-BE.log
config.weight=50
4. 前端文件配置
前端工程/public/script.js有如下配置,如果没有改过后端端口和接口地址的话不需要改
// ======== FOR Album ========
// 配置获取相片的后端API
let albumBaseURL = "http://192.168.1.100:28081";
let countDown = 3000; // 切换间隔时间
let getPhotoAPI = "http://192.168.1.100:28080/api/getPhoto";
// ======== FOR Episode ========
// 配置获取影视信息的后端API
let getMediaAPI = "http://192.168.1.100:28080/api/getEpisode";
let episodeBaseURL = "https://image.tmdb.org/t/p/original";
// let episodeBaseURL = "https://image.tmdb.org/t/p/w500";
// ======== FOR Horizon ========
// 配置Horizon页面中,获取海报和背景图的策略
// 背景图获取策略:1 - 只获取 poster;2 - 只获取 backdrop;3 - 按比例间隔获取
const BACKGROUND_STRATEGY = 3; // 默认设置为按比例间隔获取
// 如果使用策略3,可以定义比例 x 和 y
const POSTER_COUNT = 1; // 每 x 张 poster 获取 y 张 backdrop
const BACKDROP_COUNT = 1;
后端接口列表
获取相片
/api/getPhoto
该接口会从 albumPath 库中随机获得一个目录地址,在从里面随机获得一张图片,对应sql如下
SELECT album_path FROM albumPath ORDER BY RAND() LIMIT 1
你可以结合下面的这个接口来实现:
/api/setProcedureMode
更改图片获取模式,随机或获得推荐目录下的图片
接口参数
-
mode
- 0:获取随机目录下的图片地址
- 1:获得 recommand =1 的目录的图片(需要修改数据库字段值)
/api/setProcedureMode?procedureMode=1
添加影视剧
/api/updateMovie
你可以通过这个接口批量添加已有电影信息
会遍历配置文件 paths.tv 指定的文件夹,并获得文件文件名称和年份信息后,通过TMDB的接口查询详细信息和图片,并落库
paths.movie 下应该直接是电影目录,不会遍历里面的子目录
建议标记电影年份,不然可能影响TMDB查询的正确性
Your Movie Directory
**── Akira(1988)
**── BLUE GIANT (2023)
/api/updateTV
你可以通过这个接口批量添加已有电视剧信息
会遍历配置文件 paths.tv 指定的文件夹,并获得文件文件名称和年份信息后,通过TMDB的接口查询详细信息和图片,并落库(根据tmdbid去重)
paths.tv 下应该直接是电影信息,不会遍历里面的子目录
建议标记电视剧年份,不然可能影响TMDB查询的正确性
Your Dorama Directory
**── Friends
**── Severance (2022)
/api/save-TV-by-tmdb
根据tmdb地址,添加电视剧(根据tmdbid去重)
/api/save-TV-by-tmdb?url=https://www.themoviedb.org/tv/64492
/api/save-Movie-by-tmdb
根据tmdb地址,添加电影(根据tmdbid去重)
/api/save-TV-by-tmdb?url=https://www.themoviedb.org/movie/149-akira
获取影视
/api/getEpisode
该接口会从 episode 库中随机获得一个影视信息,对应sql如下
ELECT * FROM episode WHERE category != 1 ORDER BY RAND() LIMIT 1
你可以结合下面的两个接口来实现:
- 根据category字段值来获得影视信息,比如获得喜欢的影视
- 配置是否获得 季海报 和 集封面
配置影视获取模式
/api/setWeight
在获取影视信息时会生成一个1-100的随机数,若随机数小于权重,则不会请求TMDB接口获取 季海报 和 集封面图。这个接口用于设置该权重。
/api/setWeight?weight=100
/api/setCatagory
配置获取的影视剧分组,对应数据库sql为:
ELECT * FROM episode WHERE category = 2 ORDER BY RAND() LIMIT 1
category取值:
- 0:默认值
- 1:不想展示的剧集可设置成1
- 2-127:自定义分组,结合**/api/getEpisode**接口可实现获取固定分组的剧集信息
接口参数
/api/setCatagory?catagory=0
图片转码
项目支持获取RAW图片,在获得RAW图片时,会从转码后的目录中寻找同名文件:
- 若有则返回
- 若找不到,则在当前目录下寻找非RAW图片
常规前端项目使用原生HTML,只支持非RAW格式的图片,如果你想展示RAW格式的图片可以通过这个脚本实现转码
非RAW:jpg、jpeg、png
已支持的RAW:dng、cr2、heic
依赖库
# 创建并激活虚拟环境
python3 -m venv venv
source venv/bin/activate
# 更新 pip
python -m pip install --upgrade pip
# 安装系统依赖(Ubuntu/Debian)
sudo apt update
sudo apt install libraw-dev libheif-dev
# 安装 Python 依赖 临时使用阿里云的源
pip install rawpy imageio pillow pyheif -i https://mirrors.aliyun.com/pypi/simple/
转码脚本
import os
import logging
from PIL import Image
import time
import pyheif
import rawpy
import imageio
# ================= 配置参数(你可以修改这些变量)=================
SOURCE_DIR = "/vol4/1000/ROOM4/Gallery/convertTask/toconvert" # 要扫描的源文件夹路径
OUTPUT_DIR = "/vol4/1000/ROOM4/Gallery/Converted" # 输出 jpg 的统一目录
# 支持的原始格式列表
#SUPPORTED_EXTENSIONS = ('.heic', '.cr2', '.dng', '.HEIC', '.CR2', '.DNG')
SUPPORTED_EXTENSIONS = ('.dng', '.DNG')
#SUPPORTED_EXTENSIONS = ('.cr2', '.CR2')
#SUPPORTED_EXTENSIONS = ('.heic', '.HEIC')
# 设置日志记录
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s',
filename='conversion.log',
filemode='w'
)
console_handler = logging.StreamHandler()
console_handler.setLevel(logging.INFO)
console_handler.setFormatter(logging.Formatter('%(asctime)s - %(levelname)s - %(message)s'))
logging.getLogger().addHandler(console_handler)
# ================= 图像转换函数 =================
def convert_heic_to_jpeg(heic_path, output_path):
"""
使用 pyheif 将 HEIC 文件转换为 JPEG
"""
try:
heif_file = pyheif.read(heic_path)
img = Image.frombytes(
heif_file.mode,
heif_file.size,
heif_file.data,
"raw",
heif_file.mode,
heif_file.stride,
)
img.save(output_path, "JPEG", quality=95)
return True
except Exception as e:
logging.error(f"HEIC 转换失败: {heic_path},原因: {e}")
return False
def convert_raw_to_jpeg(raw_path, output_path):
"""
使用 PIL 将 CR2 文件转换为 JPEG
"""
try:
with Image.open(raw_path) as img:
if img.mode in ("RGBA", "P"):
img = img.convert("RGB")
img.save(output_path, "JPEG", quality=95)
return True
except Exception as e:
logging.error(f"RAW 文件转换失败 (PIL): {raw_path},原因: {e}")
return False
def convert_dng_with_rawpy(dng_path, output_path):
"""
使用 rawpy 将 DNG 文件转换为 JPEG
"""
try:
with rawpy.imread(dng_path) as raw:
rgb = raw.postprocess()
imageio.imwrite(output_path, rgb)
return True
except Exception as e:
logging.error(f"DNG 转换失败 (rawpy): {dng_path},原因: {e}")
return False
def convert_to_jpeg(input_path, output_dir):
"""
将图像文件转换为 JPEG 格式,并保存至 output_dir
:param input_path: 原始文件路径
:param output_dir: 输出目录
:return: 转换成功与否
"""
try:
base_name = os.path.splitext(os.path.basename(input_path))[0]
output_path = os.path.join(output_dir, f"{base_name}.jpg")
if os.path.exists(output_path):
logging.info(f"已存在,跳过: {input_path}")
return False
logging.info(f"正在转换: {input_path}")
ext = os.path.splitext(input_path)[1].lower()
if ext == '.heic':
success = convert_heic_to_jpeg(input_path, output_path)
elif ext == '.dng':
success = convert_dng_with_rawpy(input_path, output_path)
else:
success = convert_raw_to_jpeg(input_path, output_path)
return success
except Exception as e:
logging.error(f"转换失败: {input_path},原因: {e}")
return False
def find_files(source_dir, extensions):
"""
递归查找所有符合条件的文件
"""
matched_files = []
for root, _, files in os.walk(source_dir):
for file in files:
if file.lower().endswith(extensions):
matched_files.append(os.path.join(root, file))
return matched_files
def main():
# 检查目录是否存在
if not os.path.isdir(SOURCE_DIR):
logging.error(f"源目录不存在: {SOURCE_DIR}")
return
if not os.path.exists(OUTPUT_DIR):
os.makedirs(OUTPUT_DIR)
logging.info(f"创建输出目录: {OUTPUT_DIR}")
# 查找所有需要转换的文件
raw_files = find_files(SOURCE_DIR, SUPPORTED_EXTENSIONS)
total = len(raw_files)
success_count = 0
failed_count = 0
logging.info(f"共找到 {total} 个需要转换的文件.")
for i, file_path in enumerate(raw_files, start=1):
base_name = os.path.splitext(os.path.basename(file_path))[0]
output_jpg = os.path.join(OUTPUT_DIR, f"{base_name}.jpg")
if os.path.exists(output_jpg):
logging.info(f"[{i}/{total}] 已存在,跳过: {file_path}")
continue
result = convert_to_jpeg(file_path, OUTPUT_DIR)
if result:
logging.info(f"[{i}/{total}] 成功转换: {file_path}")
success_count += 1
else:
logging.warning(f"[{i}/{total}] 失败或跳过: {file_path}")
failed_count += 1
print("-" * 60)
logging.info(f"转换完成!成功: {success_count},失败/跳过: {failed_count}")
logging.info(f"总耗时: {time.time() - start_time:.2f} 秒")
if __name__ == "__main__":
start_time = time.time()
main()
java配置文件
需要修改java项目配置文件
# RAW 转码后的图片地址
paths.converted= 转码后文件存放目录







 2025-6-4 22:55:16
2025-6-4 22:55:16

