前言
AudioDock 又双叒叕更新了!这次更新带来的是音频入库能力的扩展和 TTS(文本转语音)服务的增强!
正文
1. 更多音频格式支持入库
之前 AudioDock 在音频入库时对格式有一定限制,这次更新大幅扩展了支持的音频格式范围。现在你可以将更多类型的音频文件导入到 AudioDock 库中,服务端也做了相应的格式兼容处理,入库体验更顺畅。
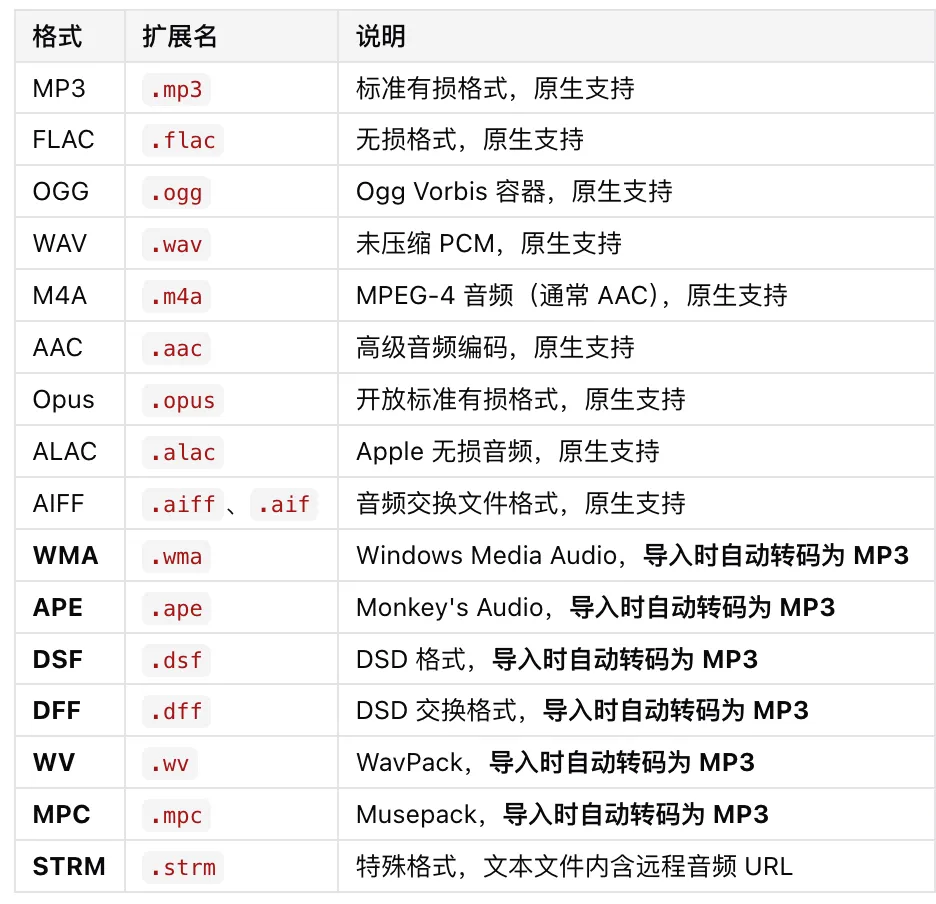
同时修复了入库过程中可能出现的报错问题,让批量导入更加稳定。
2. 新增小米、MiniMax TTS 服务
TTS(文本转语音)功能迎来了新成员——小米、MiniMax TTS 引擎。小米 TTS 提供了多种音色选择,覆盖了不同的使用场景。在 AudioDock 的桌面端、移动端,都可以选择小米 TTS 来生成语音内容。
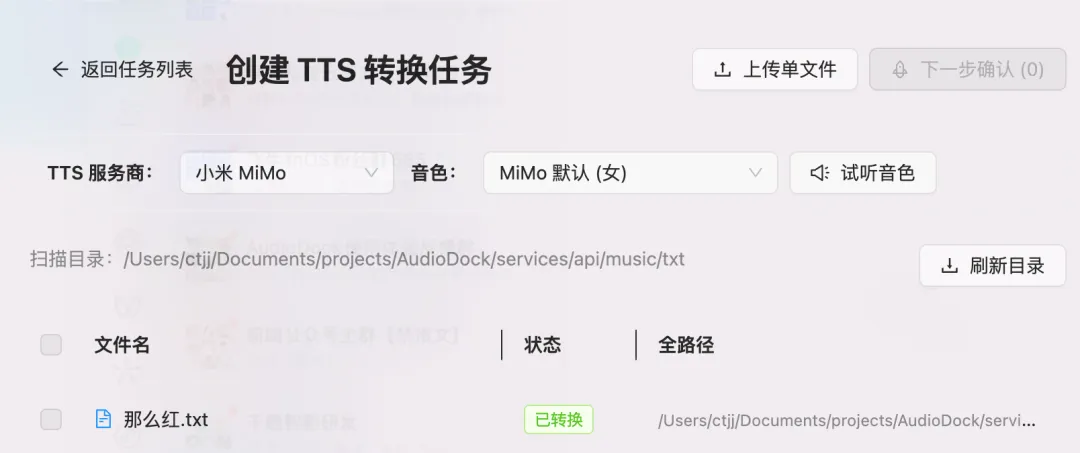
MiniMax 的语音合成质量在业界口碑不错,音色自然度高,适合对语音质量有更高要求的场景。
现在 AudioDock 的 TTS 服务已经支持多个引擎:Edge、MiniMax 和小米,用户可以根据需求自由切换。
3. TTS 引擎架构优化
这次更新对 TTS 服务的引擎架构做了重构,引入了统一的引擎注册机制(Registry),新增引擎更加方便。各引擎的接口也做了标准化,后续接入更多 TTS 服务会更轻松。
4. 其他改进
- • 修复了转码后 MP3 的播放服务问题
- • 数据库 Schema 更新,支持新的 TTS 相关字段
- • 三端(桌面端/移动端/小程序)继续播放逻辑统一优化
最后
本次 AudioDock 的核心更新可以概括为两点:音频入库更自由(支持更多格式)和 TTS 选择更丰富(新增小米和 MiniMax 引擎)。如果你已经在用 AudioDock,建议更新到最新版本体验这些新功能。
项目的 GitHub 仓库是 https://github.com/mmdctjj/AudioDock,欢迎 Star 和提 Issue。
今天的分享就这些了,感谢大家的阅读,如果文章中存在错误的地方欢迎指正!







 2026-5-31 15:22:05
2026-5-31 15:22:05

